Google 财经的法律实体创建
结账并不是某一个瞬间。它是一条可审计的追溯链。当关键字段无法追溯到其来源时,信任就会崩塌,取而代之的是反复猜疑和各种变通办法。
我是在 Google Finance 内部一个跨职能小组(pod)里负责这个项目的 UX 工程师。我们在构建一套用于法务实体创建的内部工作流(内部代号 Introspect)。我与产品设计师、UX 文案以及软件工程师/数据合作伙伴紧密协作;我的重点是把一个混乱、跨多系统的流程落成可交付的 UI:可靠的组件、可投产的交互,以及用于验证成效的埋点与度量体系。
最初的现实很普通,但代价很高:实体分散在多个系统里,标签不一致;汇总在边界情况下会崩;还有“影子表格”试图把故事讲清楚。目标不是做一份更好看的报表,而是做一套人们在关账(close)和创建实体时都能信任的系统:一个唯一的规范身份(canonical identity)、清晰的责任归属,以及你可以验证的新鲜度。
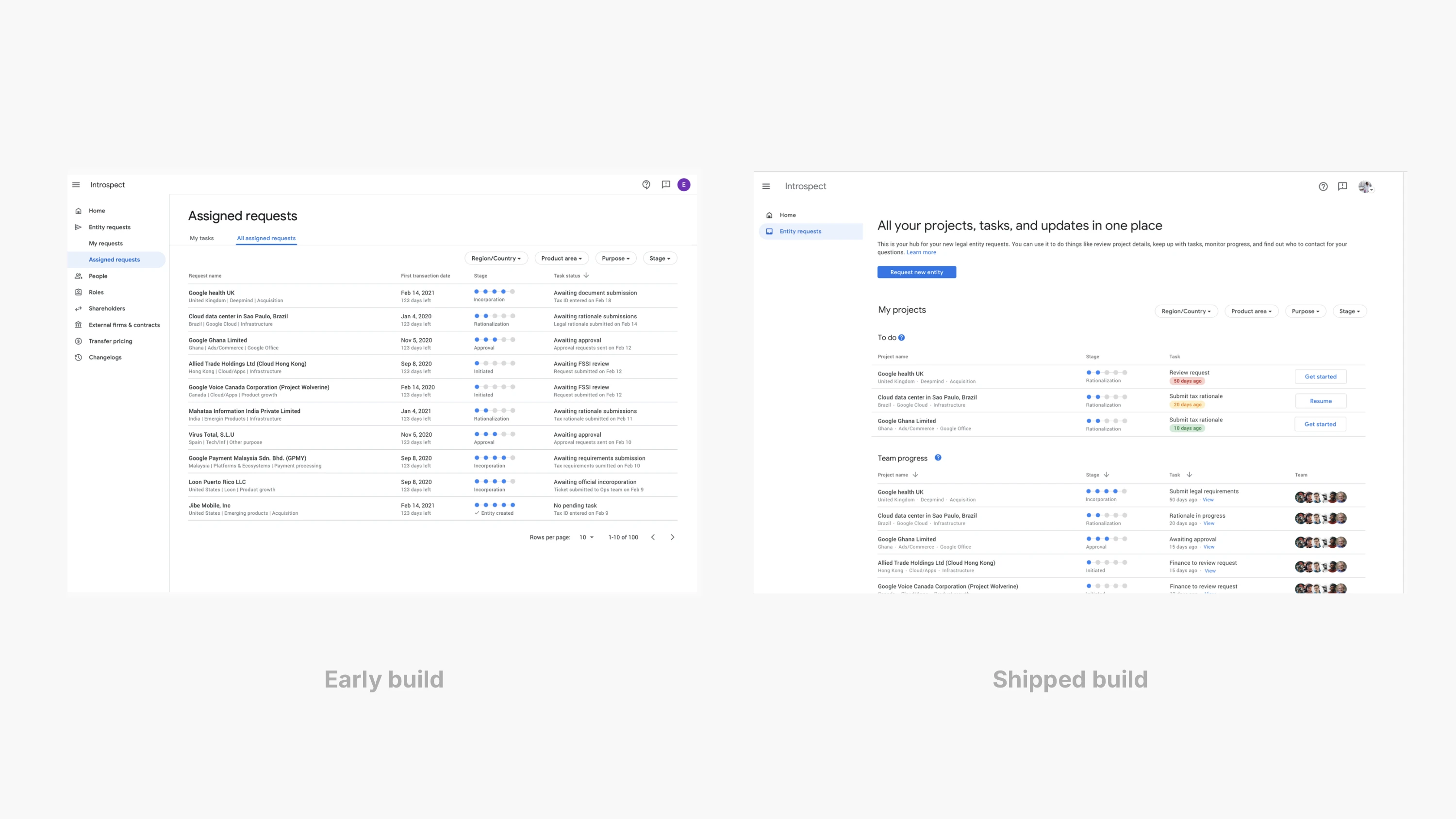
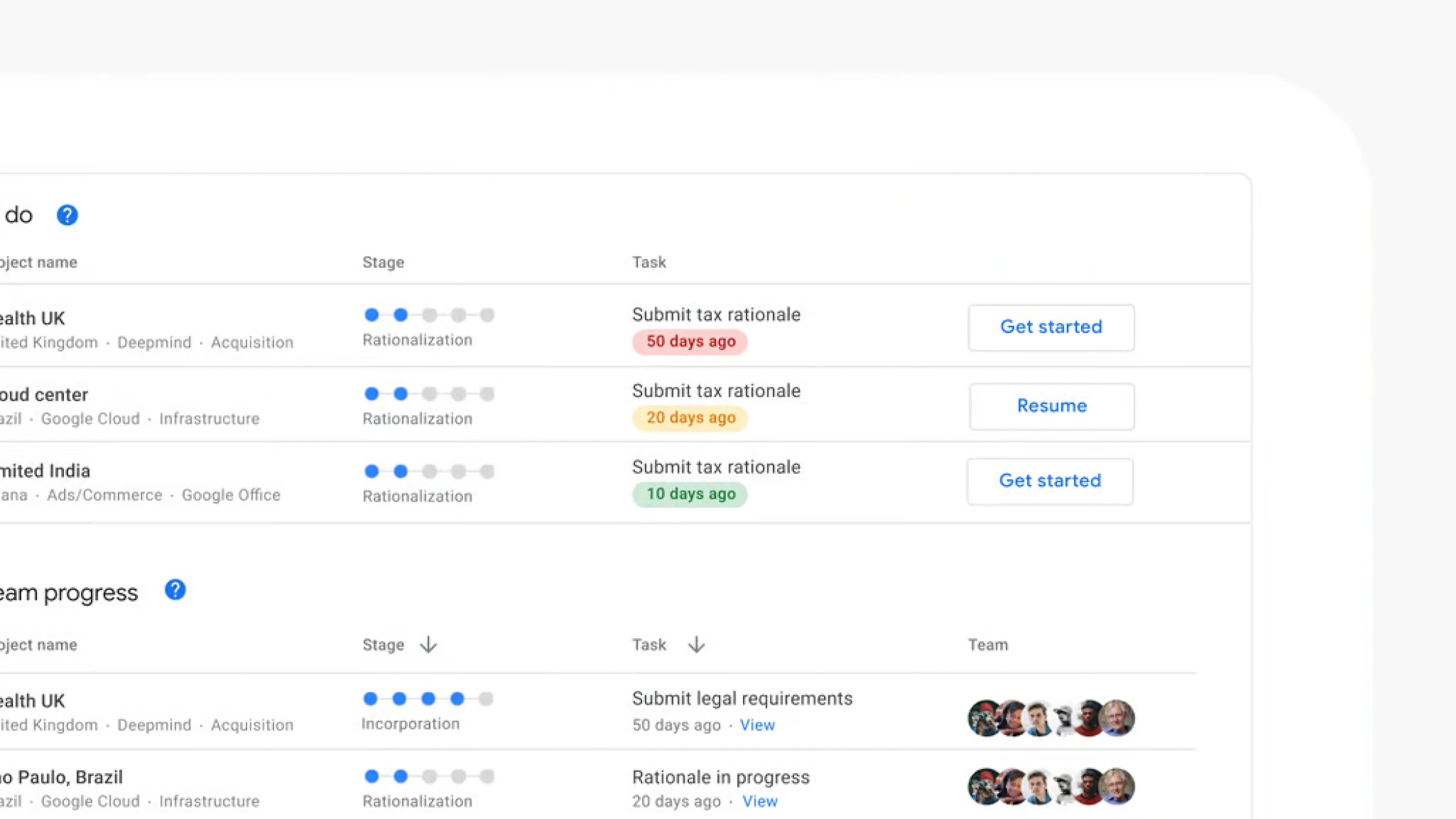
这意味着产品必须像工作流一样运作,而不是像仓库一样堆放信息。我们给用户一个“主页”,能一眼回答第一个问题:我现在负责什么。“My projects”和“Team progress”让工作变得可读,而不需要用户从邮件里拼凑上下文。每一行都像一句紧凑的状态描述:所处阶段、下一步任务、停留时长、相关人是谁。卡住了就显得卡住;在等人就明确说在等谁。
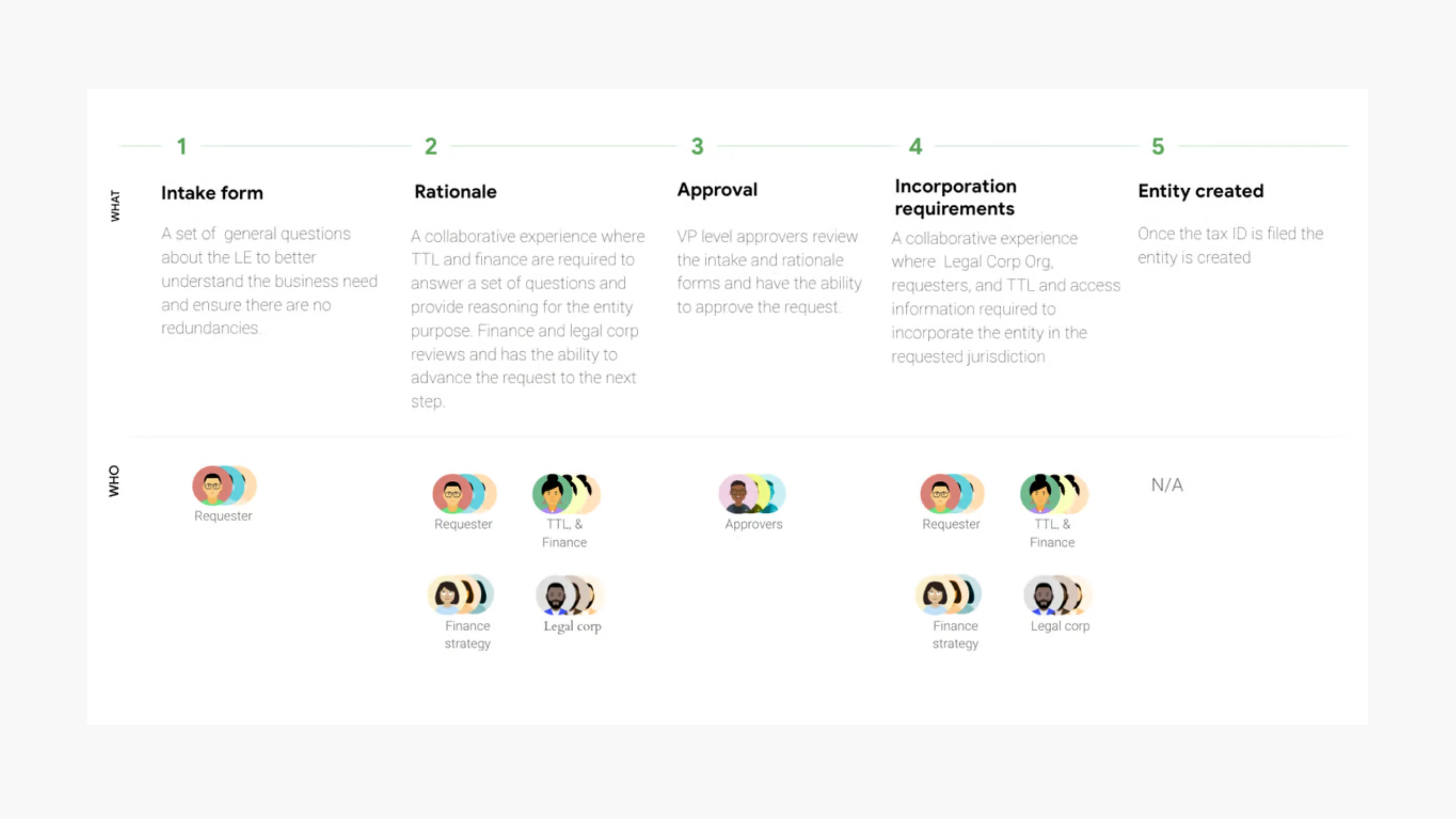
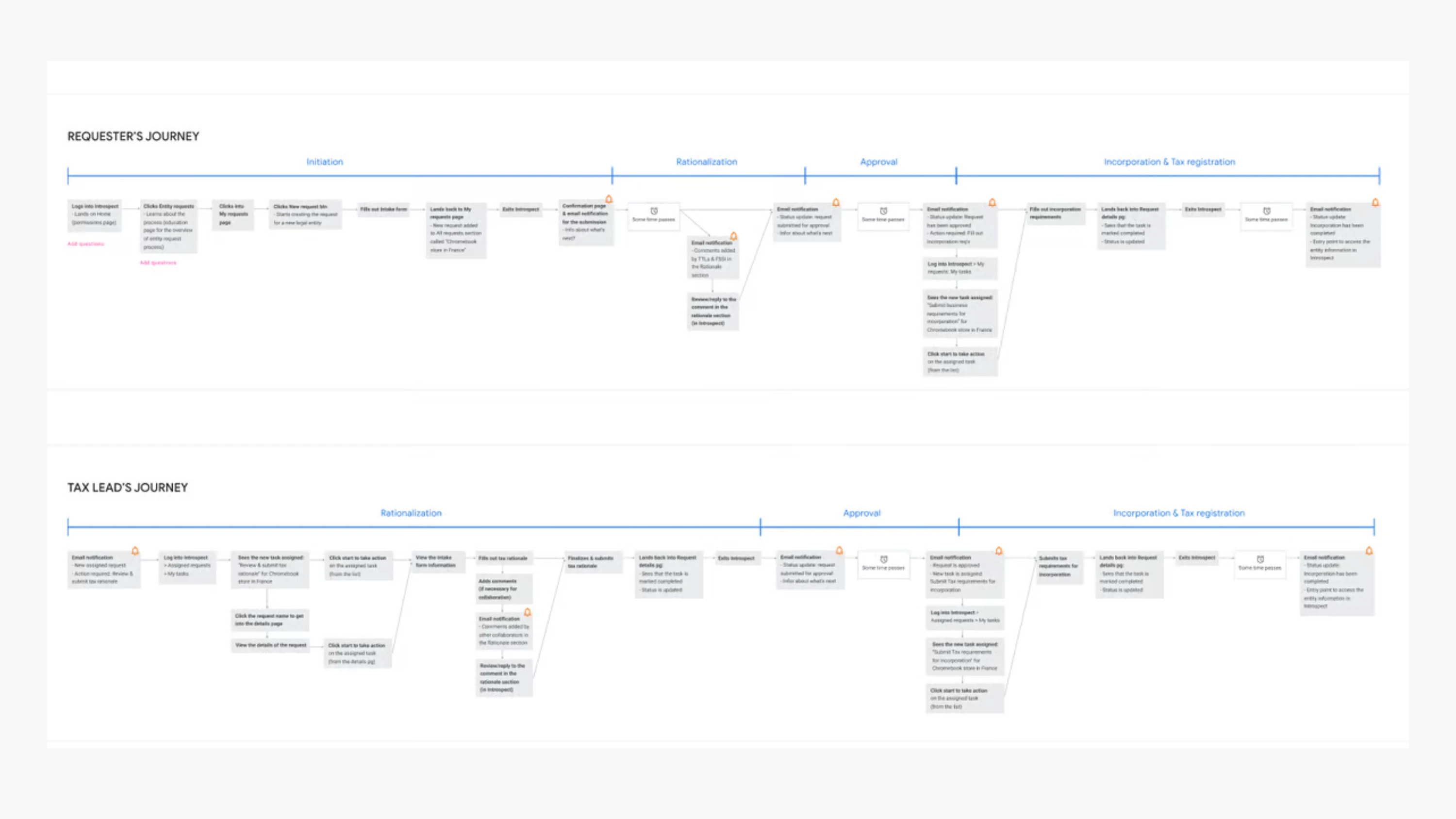
创建流程同样需要这种纪律。请求表单必须收集到足够信息来避免产生错误实体,但又不能把每一次请求都变成一场官僚耐力赛。所以我们采用结构化、分步骤的流程:在推进的同时保持上下文可见,并把要求说清楚。与其堆一整页政策文本,我们更依赖渐进披露(progressive disclosure):只在你正在填的字段旁,给出适用的那一点指导,用的是人们可以彼此复述的语言。评论与表单并排呈现,而不是埋在另一个线程里,因为审阅是社会化的过程,而“为什么这样做”的记录几乎和“做了什么”的记录同样重要。
在 UI 之下,我们把“身份”当作锚点来设计。每个实体都解析到一个规范 ID;页面会告诉你它是什么、映射到哪里、缺了什么、以及上一次刷新是什么时候。新鲜度和完整度不是装饰性的元数据;它们决定了关账时你是有信心,还是只能反复猜测。当某个来源不完整或数据链路失败时,界面会明确指出是哪个来源出了问题,让不确定性可见,而不是悄无声息地潜伏。
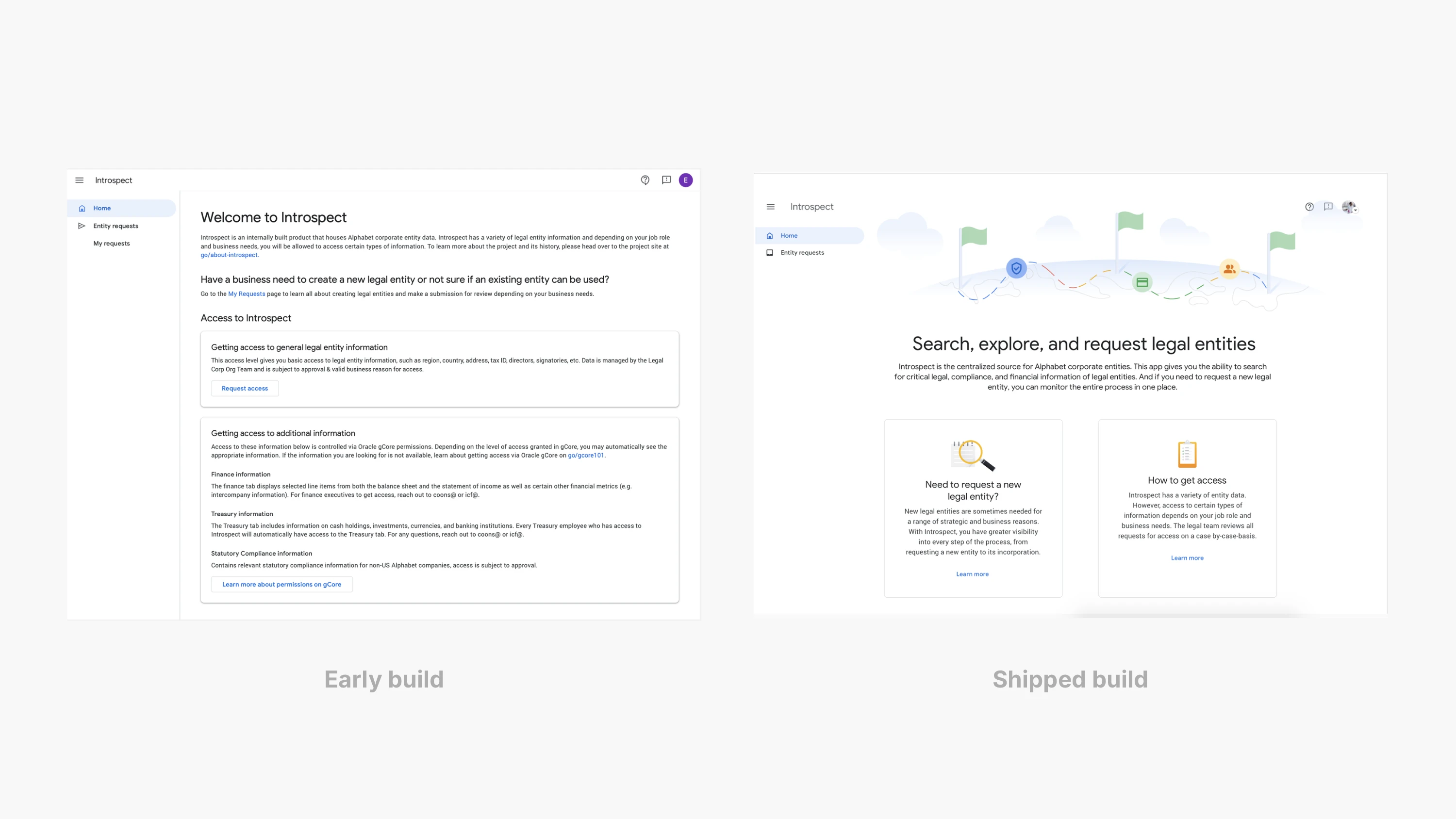


实体一旦存在,审阅者仍然需要把数字当作“证据”来读,而不是当作“断言”来接受。所以我们让操作路径保持克制且可逆:找到实体、选择期间、应用一组经过验证的筛选维度,然后阅读一张你可以当场讲清楚的表格。下钻在原地展开以保持上下文;血缘(lineage)在侧边打开,让你可以把一个数追溯到来源而不丢位置,并且能无缝返回,不用从头再来。
差异(variance)需要一种解释方式,能匹配系统真实的变化方式。我们给用户一个结构化的方法,把“为什么”附着在“是什么”上,让常见原因一眼可见、少见原因更突出:汇率(FX)、映射变更、一次性调整、时间差、晚到数据。备注可以固定在行上,这样下一位审阅者不用从零开始,也让压力下做出的决定留下可读的轨迹。
无障碍(accessibility)不是最后的抛光。它从早期就塑造了界面:可预测的焦点顺序、清晰的标签、以及在不使用鼠标时也站得住的布局。实际效果是产品对所有人都更“安静”、更稳定——因为同一套纪律既帮助辅助技术,也帮助关账时疲惫的人类。
我们和数据科学合作伙伴一起度量基础行为:项目创建开始与完成、筛选应用、下钻打开、血缘查看、备注创建、导出,以及用户跳回表格作为变通方案的频率。更实际的信号是“拿到第一个答案的时间”和“审阅后的返工率”。护栏指标是新鲜度与完整度,因为信任很难建立,却很容易失去。
最终结果很克制、也很有效:请求推进时需要的交接更少;审阅减少了重建上下文的成本;而当某个东西看起来不对时,你可以追溯到来源,并留下让下一次审阅更快的备注。早期用户反馈里,有一次注册从“发起到完成注册……16 天”,而这一更大范围的工作也在内部因 UX 质量获得认可。♦
我是在 Google Finance 内部一个跨职能小组(pod)里负责这个项目的 UX 工程师。我们在构建一套用于法务实体创建的内部工作流(内部代号 Introspect)。我与产品设计师、UX 文案以及软件工程师/数据合作伙伴紧密协作;我的重点是把一个混乱、跨多系统的流程落成可交付的 UI:可靠的组件、可投产的交互,以及用于验证成效的埋点与度量体系。
最初的现实很普通,但代价很高:实体分散在多个系统里,标签不一致;汇总在边界情况下会崩;还有“影子表格”试图把故事讲清楚。目标不是做一份更好看的报表,而是做一套人们在关账(close)和创建实体时都能信任的系统:一个唯一的规范身份(canonical identity)、清晰的责任归属,以及你可以验证的新鲜度。
这意味着产品必须像工作流一样运作,而不是像仓库一样堆放信息。我们给用户一个“主页”,能一眼回答第一个问题:我现在负责什么。“My projects”和“Team progress”让工作变得可读,而不需要用户从邮件里拼凑上下文。每一行都像一句紧凑的状态描述:所处阶段、下一步任务、停留时长、相关人是谁。卡住了就显得卡住;在等人就明确说在等谁。
创建流程同样需要这种纪律。请求表单必须收集到足够信息来避免产生错误实体,但又不能把每一次请求都变成一场官僚耐力赛。所以我们采用结构化、分步骤的流程:在推进的同时保持上下文可见,并把要求说清楚。与其堆一整页政策文本,我们更依赖渐进披露(progressive disclosure):只在你正在填的字段旁,给出适用的那一点指导,用的是人们可以彼此复述的语言。评论与表单并排呈现,而不是埋在另一个线程里,因为审阅是社会化的过程,而“为什么这样做”的记录几乎和“做了什么”的记录同样重要。
在 UI 之下,我们把“身份”当作锚点来设计。每个实体都解析到一个规范 ID;页面会告诉你它是什么、映射到哪里、缺了什么、以及上一次刷新是什么时候。新鲜度和完整度不是装饰性的元数据;它们决定了关账时你是有信心,还是只能反复猜测。当某个来源不完整或数据链路失败时,界面会明确指出是哪个来源出了问题,让不确定性可见,而不是悄无声息地潜伏。
实体一旦存在,审阅者仍然需要把数字当作“证据”来读,而不是当作“断言”来接受。所以我们让操作路径保持克制且可逆:找到实体、选择期间、应用一组经过验证的筛选维度,然后阅读一张你可以当场讲清楚的表格。下钻在原地展开以保持上下文;血缘(lineage)在侧边打开,让你可以把一个数追溯到来源而不丢位置,并且能无缝返回,不用从头再来。
差异(variance)需要一种解释方式,能匹配系统真实的变化方式。我们给用户一个结构化的方法,把“为什么”附着在“是什么”上,让常见原因一眼可见、少见原因更突出:汇率(FX)、映射变更、一次性调整、时间差、晚到数据。备注可以固定在行上,这样下一位审阅者不用从零开始,也让压力下做出的决定留下可读的轨迹。
无障碍(accessibility)不是最后的抛光。它从早期就塑造了界面:可预测的焦点顺序、清晰的标签、以及在不使用鼠标时也站得住的布局。实际效果是产品对所有人都更“安静”、更稳定——因为同一套纪律既帮助辅助技术,也帮助关账时疲惫的人类。
我们和数据科学合作伙伴一起度量基础行为:项目创建开始与完成、筛选应用、下钻打开、血缘查看、备注创建、导出,以及用户跳回表格作为变通方案的频率。更实际的信号是“拿到第一个答案的时间”和“审阅后的返工率”。护栏指标是新鲜度与完整度,因为信任很难建立,却很容易失去。
最终结果很克制、也很有效:请求推进时需要的交接更少;审阅减少了重建上下文的成本;而当某个东西看起来不对时,你可以追溯到来源,并留下让下一次审阅更快的备注。早期用户反馈里,有一次注册从“发起到完成注册……16 天”,而这一更大范围的工作也在内部因 UX 质量获得认可。♦
{kind=link}